1. 相邻数对
问题描述
给定
输入格式
- 第一行:整数
(给定整数的个数) - 第二行:
个整数
输出格式
输出值相差
数据范围
- 整数范围:
的非负整数
输入样例
6
10 2 6 3 7 8输出样例
3样例说明
值相差
思路:排序 + 遍历
- 对数组排序
- 遍历排序后的数组,统计相邻元素差值为
的次数
- 时间复杂度:
(排序主导) - 空间复杂度:
notice
题目保证所有输入整数都不相同,因此排序后只需检查相邻元素是否满足
a[i] - a[i-1] == 1,每次满足就计数加 1,如果是求数对个数的话对应的结果应该是所有满足条件的相邻元素对的个数即i*j,其中 i 和 j 分别是两个相邻元素的出现次数。
代码实现
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1010;
int a[N];
int main(){
int n;
cin >> n;
for(int i = 1; i <= n; ++i)
cin >> a[i];
// 排序数组
sort(a + 1, a + n + 1);
// 统计相邻差值为 1 的个数
int res = 0;
for(int i = 2; i <= n; ++i){
if(a[i] - a[i-1] == 1)
res++;
}
cout << res << endl;
return 0;
}2. 画图
问题描述
给定
输入格式
- 第一行:整数
- 接下来
行:每行四个整数 ,表示矩形的左下角和右上角坐标
输出格式
输出覆盖的格点数量。
数据范围
输入样例
2
1 1 4 4
2 3 6 5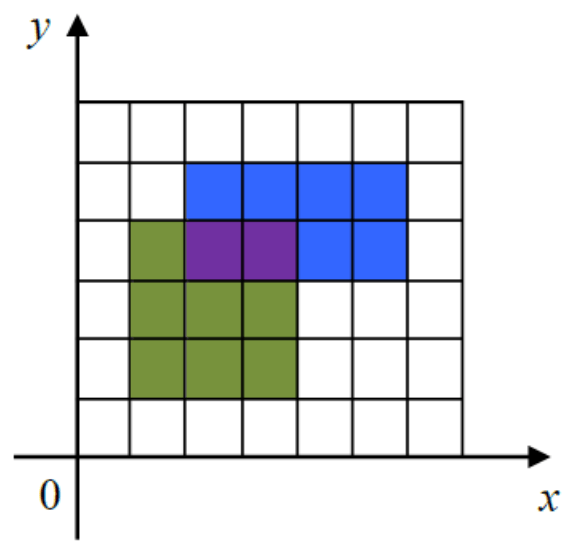
输出样例
15思路:暴力枚举
遍历所有可能的格点,检查每个格点是否被至少一个矩形覆盖,若覆盖了就 break。
- 时间复杂度:
- 空间复杂度:
代码实现
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 101;
int a[N],b[N],c[N],d[N];
int x,y;
int main(){
int n;cin >> n;
int res = 0;
for(int i = 1;i<=n;++i){
cin >> a[i] >> b[i] >> c[i] >> d[i];
}
for(int x = 0;x<=100;++x)
for(int y = 0;y<=100;++y)
for(int i = 1;i<=n;++i){
if(x >= a[i] && y >= b[i] && x+1 <= c[i] && y+1 <= d[i]){
res++;
break;
}
}
cout << res << endl;
return 0;
}3.字符串匹配
问题描述
给定一个字符串
- 选项为
1:大小写敏感(’A’ ≠ ‘a’) - 选项为
0:大小写不敏感(’A’ = ‘a’)
输入格式
- 第一行:字符串
(由大小写英文字母组成) - 第二行:整数
type(0 = 不敏感,1 = 敏感) - 第三行:整数
(文字行数) - 接下来
行:每行一个待查文字(由大小写英文字母组成,无空格)
输出格式
输出包含字符串
数据范围
- 每个字符串长度:不超过 100
输入样例
Hello
1
5
HelloWorld
HiHiHelloHiHi
GrepIsAGreatTool
HELLO
HELLOisNOTHello输出样例
HelloWorld
HiHiHelloHiHi
HELLOisNOTHello样例说明
由于 type = 1(大小写敏感):
- 第 1 行
HelloWorld包含Hello✓ - 第 2 行
HiHiHelloHiHi包含Hello✓ - 第 3 行
GrepIsAGreatTool不包含Hello✗ - 第 4 行
HELLO大小写不同 ✗ - 第 5 行
HELLOisNOTHello包含Hello✓
若 type = 0(大小写不敏感),第 4 行也应输出。
思路 1:库函数
- 时间复杂度:
,其中 是行数, 是每行的平均长度 - 空间复杂度:
(存储输入的字符串)
使用 C++ 字符串的 find() 函数进行匹配:
- 大小写敏感:直接用
find()查找 - 大小写不敏感:先将两个字符串转换为小写,再用
find()查找
#include <algorithm>
#include <cstring>
#include <iostream>
using namespace std;
// 转换字符串为小写
string toLower(string s) {
string result = "";
for (auto c : s) {
result += tolower(c);
}
return result;
}
int main() {
string s;
cin >> s;
int type;
cin >> type;
int n;
cin >> n;
while (n--) {
string line;
cin >> line;
if (type == 1) {
// 大小写敏感
if (line.find(s) != string::npos)
cout << line << endl;
} else {
// 大小写不敏感:都转小写后比较
if (toLower(line).find(toLower(s)) != string::npos)
cout << line << endl;
}
}
return 0;
}4. 最优配餐
题目描述
区域为 n × n 格点图。部分格点为分店、部分为客户、部分为不可通过点。格点之间沿边可行走,相邻格点距离为 1。每份餐每走一单位距离成本为 1。每个客户有需求量 ci,可由任意分店配送(分店不限容量)。求最小配送总成本。
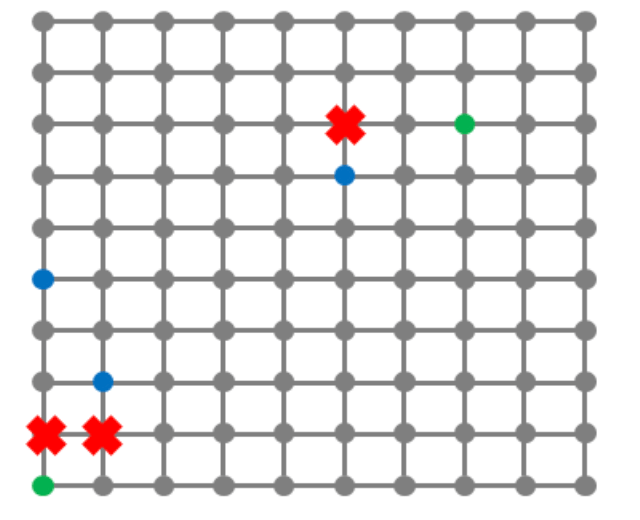
输入
- 第一行:四个整数
n m k d - 接下来
m行:每行xi yi(分店坐标) - 接下来
k行:每行xi yi ci(客户坐标与需求量,可能多客户同坐标) - 接下来
d行:每行xi yi(不可通过点)
所有坐标均在 1..n,保证每个客户都能被配送。
输出
- 一个整数:最小总配送成本
约束
1 ≤ n ≤ 10001 ≤ m, k, d ≤ n^2ci ≤ 1000
样例
输入:
10 2 3 3
1 1
8 8
1 5 1
2 3 3
6 7 2
1 2
2 2
6 8输出:
29提示:将所有分店视为多源起点做 BFS,计算每个格点到最近分店的最短距离,然后按客户位置累加 distance × demand 即可。
思路:图的多源最短路问题 + BFS
多源最短路问题和多源汇最短路问题的区别?
- 多源最短路问题:多个起点,一个终点,求最短路径
- 多源汇最短路问题:一个起点,多个终点,求最短路径
超级源点,超级源点与所有源点之间不用真的建立,直接压入所有初始源点即可
想法 1:各个分店各自做 BFS ❌
这个是不行的,因为每个客户都要对每个分店做 BFS,时间复杂度是 O(m*n^2) , m 是分店数量, n^2 是 BFS 的复杂度,会超时
想法 2:所有分店视为集体做 BFS ✅
将所有分店视为多源起点,直接压入队列,进行 BFS,每个格点的距离就是到最近分店的距离,时间复杂度是 O(n^2) , n^2 是 BFS 的复杂度
想法 3:各个客户反向 BFS ❌
每次查询都需要做 BFS,时间复杂度是 O(k*n^2) , k 是客户数量, n^2 是 BFS 的复杂度
想法 4:所有客户视为集体方向 BFS ❌
这个也是不行的,每个客户的需求量不同,无法直接压入队列,需要对每个客户单独处理,时间复杂度是 O(k*n^2) , k 是客户数量, n^2 是 BFS 的复杂度,也会超时
#include <algorithm>
#include <cstring>
#include <iostream>
#include <queue>
using namespace std;
#define x first
#define y second
typedef long long ll;
typedef pair<int, int> PII;
const int N = 1010;
queue<PII> q;
typedef struct {
int x, y, c;
} Target;
Target tg[N * N]; // 记录查询
bool g[N][N];
int dist[N][N];
int n, m, k, d;
void bfs() {
int dx[] = {-1, 0, 1, 0}, dy[] = {0, 1, 0, -1};
while (q.size()) {
auto t = q.front();
q.pop();
for (int i = 0; i < 4; ++i) {
int a = t.x + dx[i];
int b = t.y + dy[i];
if (a < 1 || a > n || b < 1 || b > n || g[a][b])
continue;
if (dist[a][b] > dist[t.x][t.y] + 1) {
dist[a][b] = dist[t.x][t.y] + 1;
q.push({a, b});
}
}
}
}
int main() {
// 提高 cin/cout 速度,或者使用 scanf 和 printf,不加会超时
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> k >> d;
memset(dist, 0x3f, sizeof dist);
// 采用超级源点的方式,直接压入所有源点
while (m--) {
int x, y;
cin >> x >> y;
dist[x][y] = 0;
q.push({x, y});
}
// 记录查询
for (int i = 0; i < k; ++i) {
cin >> tg[i].x >> tg[i].y >> tg[i].c;
}
while (d--) {
int x, y;
cin >> x >> y;
g[x][y] = true;
}
bfs();
ll res = 0;
for (int i = 0; i < k; ++i) {
res += dist[tg[i].x][tg[i].y] * tg[i].c;
}
cout << res << endl;
return 0;
}