《MoKA: Multimodal Low-Rank Adaptation for MLLMs》
一、论文基本信息
- 原文链接: https://arxiv.org/abs/2506.05191
- 项目主页: https://gewu-lab.github.io/MokA
- 作者: Yake Wei, Yu Miao, Dongzhan Zhou, Di Hu (中国人民大学、上海人工智能实验室)
- 会议: NeurIPS 2025 Oral Presentation
关键词: 多模态大语言模型 (MLLM), 低秩适配 (LoRA), 参数高效微调 (PEFT), 跨模态对齐, 模态异质性 。
二、研究背景与问题定义
研究背景
近年来,多模态大语言模型(MLLMs)在视觉语言、音频语言等任务上取得了巨大进展。当在多模态下游任务进行微调时,当前主流的多模态微调方法大多直接沿用了在纯文本大语言模型(LLMs)上发展出的微调策略,比如最经典的 LoRA。
这种简单的“照搬”策略,实际上忽略了多模态场景的本质特性——不同模态之间存在显著的异质性,单模态信息的独立建模和跨模态交互建模同等重要。然而当前的微调范式往往没有并重地显式考量这一点,导致对非文本模态的利用存在潜在局限性。
问题定义
- 模态竞争问题:由于文本指令在微调中占据主导地位,共享的 LoRA 参数往往被文本特征“霸占”,导致非文本模态(图像、音频)被边缘化,无法充分发挥其信息价值。
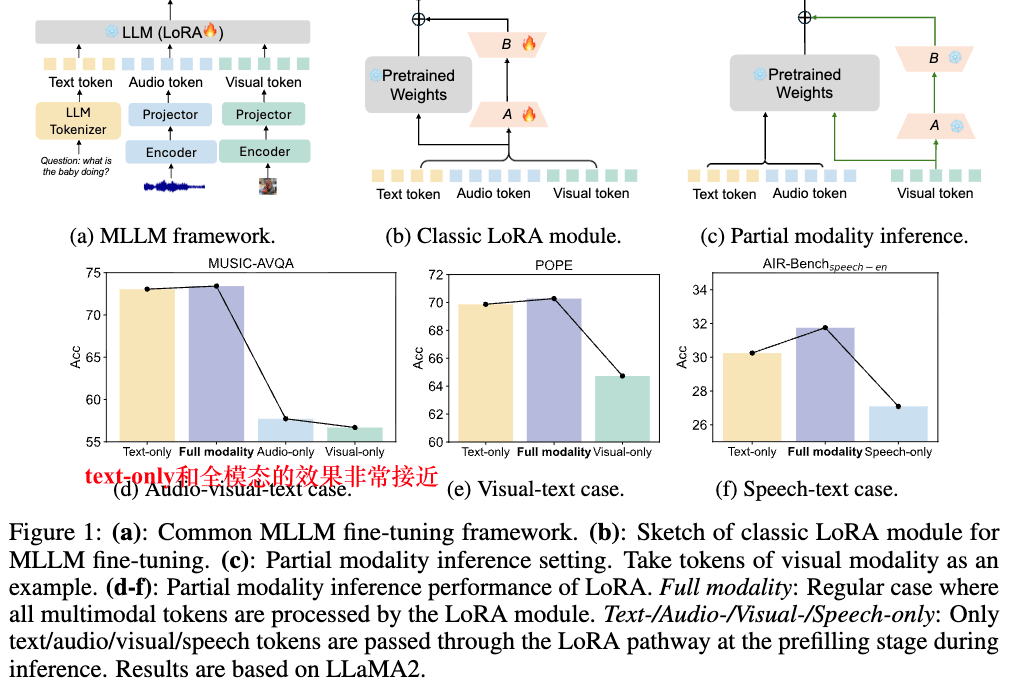
- 缺乏深度对齐:标准 LoRA 无法在低秩空间内实现显式的任务导向跨模态交互,模型很多时候只是“假装”在看图/听音频,实际上在靠文本逻辑猜答案。
- 通用性问题:已有的多模态适配方法是否能够在不同模态组合(音频-视觉-文本、视觉-文本、语音-文本)和不同 LLM 基座(LLaMA、Qwen)上都保持稳定的性能提升?
三、核心方法与设计
MoKA(Multimodal low-rank Adaptation)在保留 LoRA 核心思想(参数高效)的基础上,重新设计了低秩矩阵的作用,兼顾了单模态信息独立建模和跨模态交互建模。整个框架包含三个关键模块:
A. 模态特异的 A 矩阵(Unimodal Adaptation)
MoKA 为每个模态设置独立的投影矩阵 A,而不是像标准 LoRA 那样所有模态共享同一套参数。
- 核心思想:物理隔离各模态的梯度更新,确保每种模态的信息压缩过程不会互相干扰,避免了“模态竞争”问题。
- 作用:实现真正的单模态信息独立建模,让非文本特征能够得到充分适配。
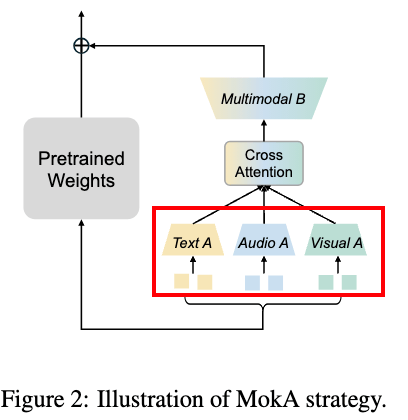
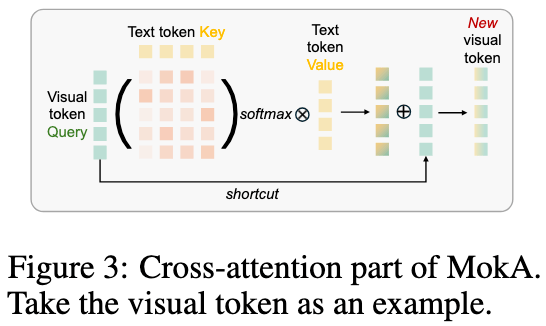
B. 任务中心的跨模态注意力(Cross-modal Interaction)
在完成单模态压缩后,MoKA 在低秩空间内引入显式的跨模态注意力机制:
- 设计:以非文本特征为 Query,文本特征(通常包含任务指令)为 Key 和 Value。
- 作用:让视觉/音频特征能够根据具体的任务指令动态调整融合权重,真正实现“带着问题看图片/听音频”,强化了任务导向的跨模态交互。
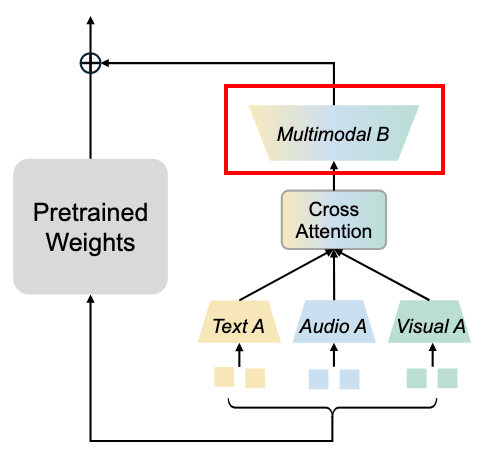
C. 模态共享的 B 矩阵(Unified Alignment)
最后,所有处理后的模态特征都通过同一个共享的矩阵 B投影回原始权重空间:
- 核心思想:在完成独立建模和深度交互后,进行统一的跨模态对齐。
- 优势:既保证了前面模块的独立性,又通过参数共享极大地控制了整体参数量,维持了 LoRA 参数高效的优点。
相比标准 LoRA 对所有模态使用相同的低秩参数,MoKA 通过“先分流处理 → 后深度交互 → 最后统一对齐”的三步设计,更好地适配了多模态场景的特性。
四、实验
1. 实验设置
覆盖了三个具有代表性的多模态任务场景,并且在多个主流 LLM 基座上验证了方法的通用性:
- 音频-视觉-文本:MUSIC-AVQA 数据集
- 视觉-文本:各类视觉问答基准,包括 POPE
- 语音-文本:AIR-Bench 数据集
- 基座模型:LLaMA 系列、Qwen 系列
2. 核心实验结果
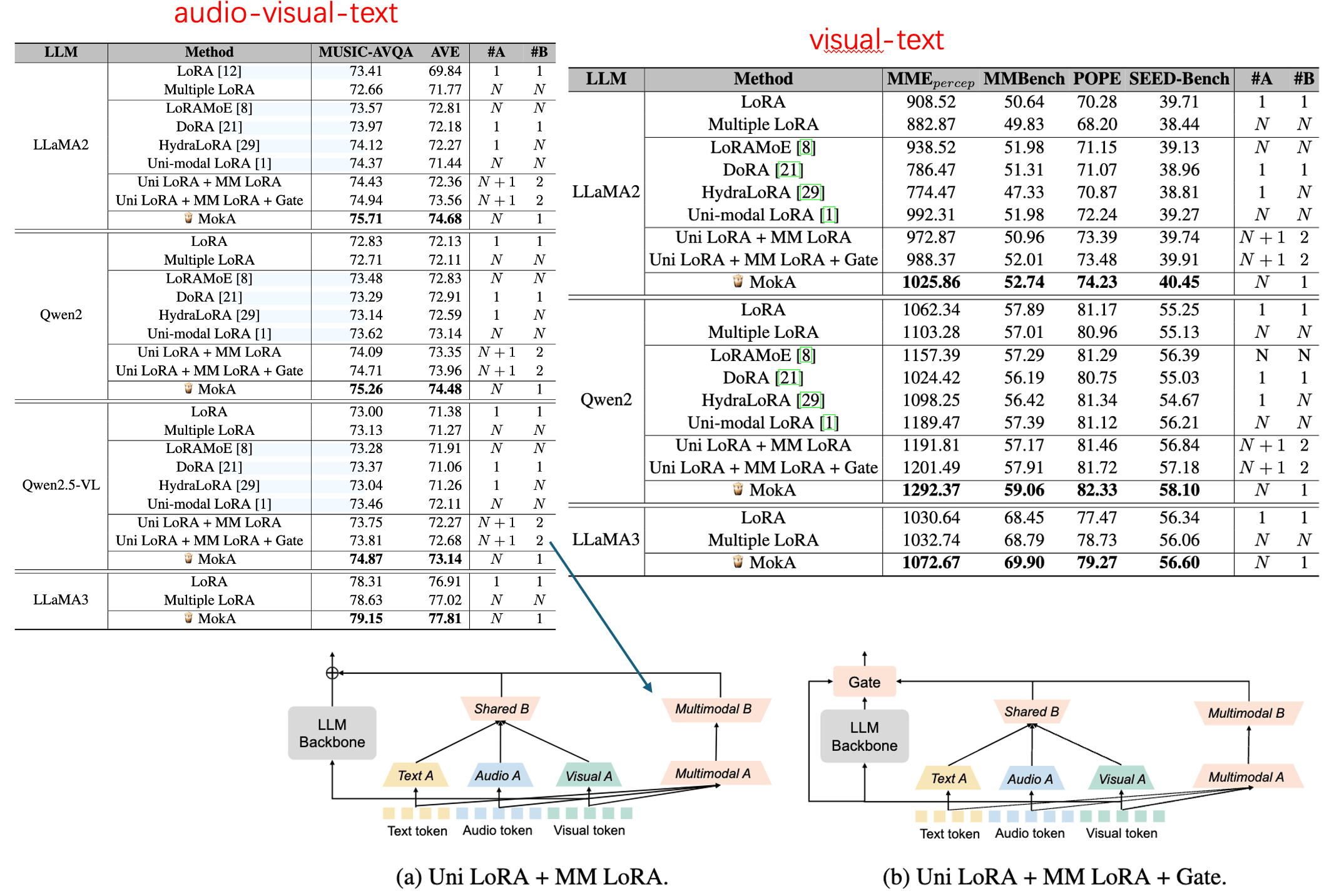
- 全面性能提升:在 MUSIC-AVQA 任务上,相比标准 LoRA 提升了约 2.3% 的准确率,在其他场景也都有 consistent 的提升。
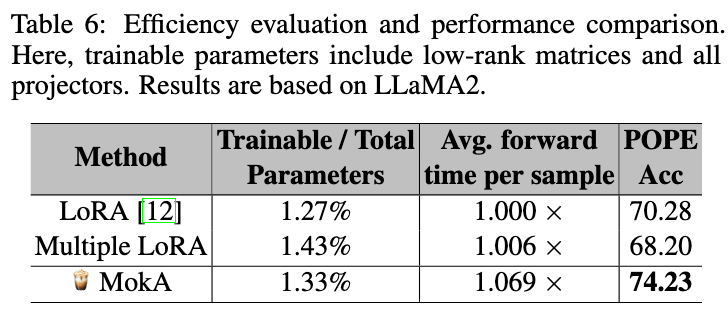
- 参数效率优异:可训练参数占比仅从标准 LoRA 的 1.20% 微增至 **1.33%**,几乎没有额外的参数开销。
- 推理延迟可控:推理延迟仅为原来的 1.069x,工程性价比极高。
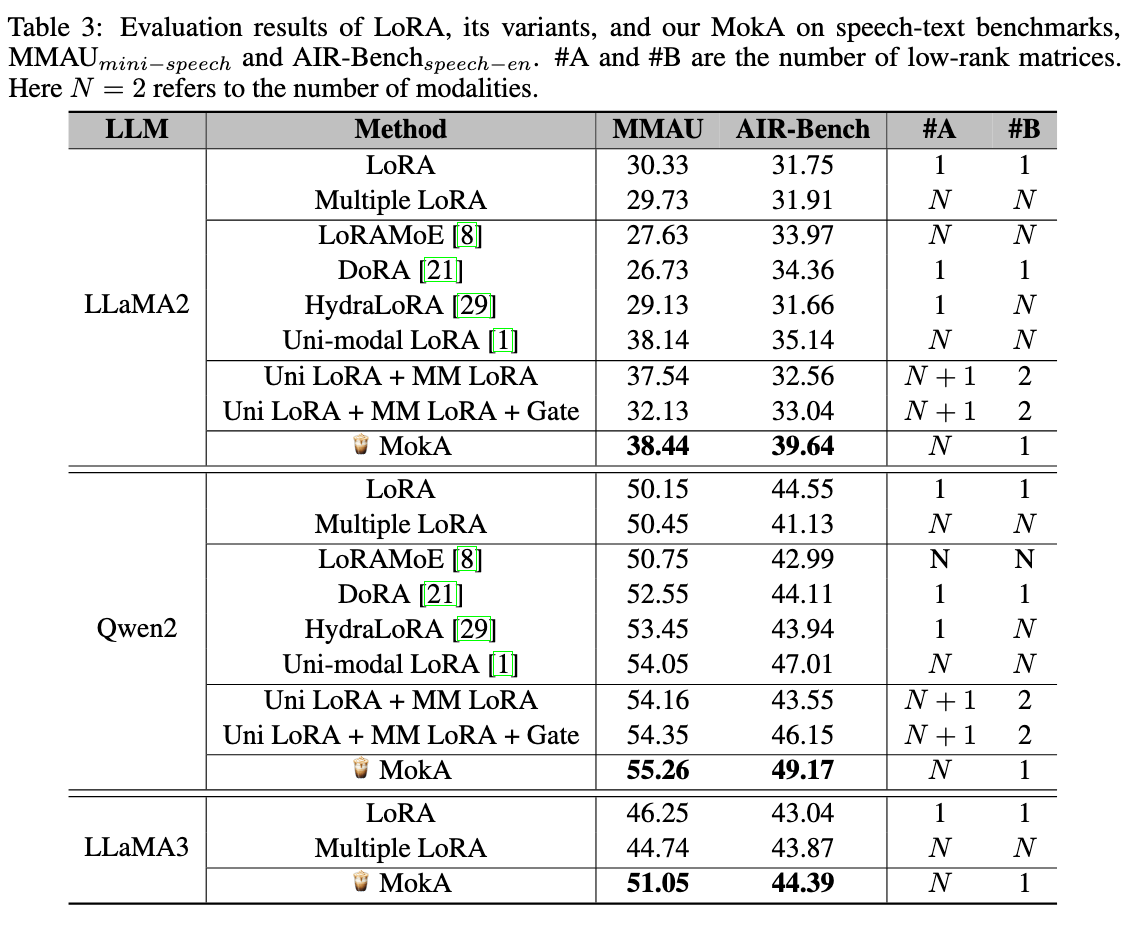
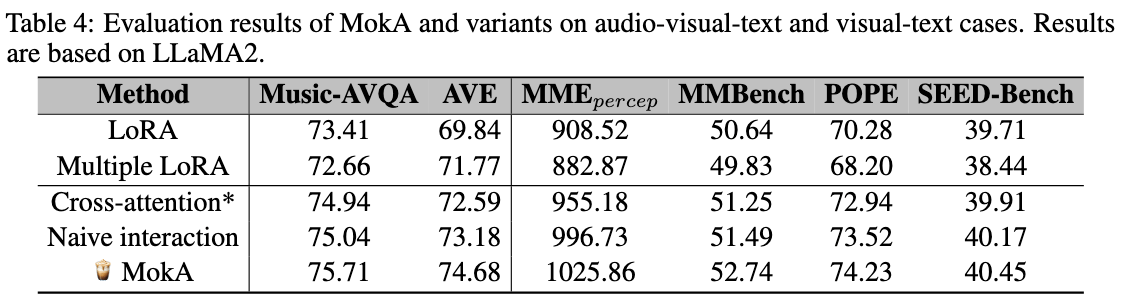
3.变体对比实验
3. 消融实验验证
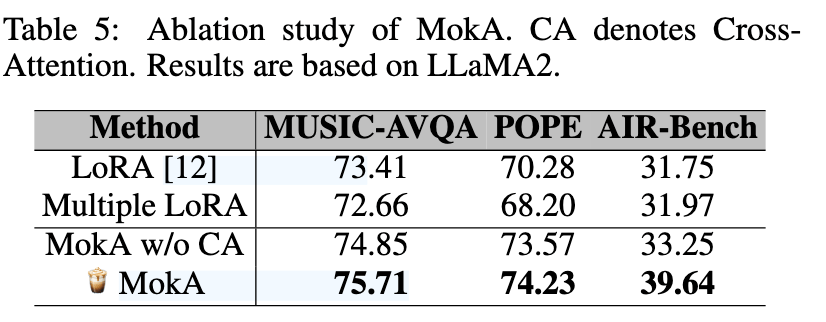
- 去掉跨模态注意力后,性能出现明显下降 → 证明仅靠独立压缩无法实现深层语义对齐。
- 模态特异 A 矩阵对性能提升贡献最大 → 验证了解决“模态竞争”问题的重要性。
4. 效率分析
五、创新点、贡献与改进空间
1. 核心创新点
- 范式创新:打破了“直接将单模态 LoRA 迁移至多模态”的惯性思维,提出了“单模态独立适配 + 显式跨模态交互 + 统一对齐”的新范式。
- 精巧设计:在不显著增加参数量和推理延迟的前提下,通过对低秩矩阵角色的重新分配,解决了多模态微调中被长期忽视的模态异质性问题。
- 通用性强:在音视文、图文、音文三种不同场景,以及多个主流 LLM 基座上都验证了性能提升,证明了方法的普适性。
2. 主要贡献
- 揭示问题本质:通过实验揭示了标准 LoRA 在多模态场景下的失效模式——模态竞争导致非文本特征被边缘化。
- 提供简洁方案:MoKA 的改动非常小,易于实现,可以直接替换现有 MLLM 微调流程中的 LoRA 模块。
- 树立新标杆:为多模态参数高效微调领域提供了新的思考方向,即必须尊重模态异质性才能实现更好的融合。
3. 局限性与改进空间
- 动态模态权重:目前模态融合的平衡因子需要手动设定,未来可以探索根据任务特性自适应调整。
- 长序列优化:在处理超长视频或极长音频时,跨模态注意力的计算效率和稳定性仍有提升空间。
- 更多模态扩展:可以进一步探索在具身智能场景中,对 LiDAR、IMU 等更多物理传感模态的适配效果。
六、我的思考
论文中的 3 个backbone 都是自回归模型,如果更换 Audio,Visual,Text token的位置,是否会对结果产生影响呢,因为这三种模态的信息密度和 token 数量是不对称的?
对于多模态微调来说,融合太早不是一件好事。MoKA 让每个模态先在自己的空间里“管好自己”,再进行交互对齐,这种思路其实在很多领域都适用。
在具身智能场景中,机器人需要处理视觉、触觉、听觉、LiDAR 等多种传感器输入,MoKA 这种对每个模态独立建模的思想非常值得借鉴,未来很有可能在机器人端侧微调中发挥作用。
论文中的 X(times) 可以表示倍数,用于运行效率比较实验中
附录添加了对除了前面提及的 3 种模态,还添加了点云模态的数据集的测试,验证了模型的泛用性
七、其他
可跟进的文献
- LoRA: Low-Rank Adaptation of Large Language Models - 标准 LoRA 原文,MoKA 的基础。
- Visual Instruction Tuning - MLLM 指令微调的经典工作。
- Flux.1 [dev] Black Forest Labs - 最近的文生图模型也使用了多模态注意力机制来处理文本条件,思路上有共通之处。
- LoRAMoE: Modality-Aware Mixture of LoRA Experts for Multimodal Adaptation - 同样是针对多模态场景改进 LoRA 的工作,通过 MoE 架构让不同模态使用不同专家,与 MoKA “让模态分开处理”的核心思想有异曲同工之妙。
- HydraLoRA: Heterogeneous Low-Rank Adaptation for Multi-Task and Multi-Modal Learning - 另一篇针对多模态/多任务场景的 LoRA 改进工作,探索了不同结构下的参数分配策略,可以对比学习不同的设计思路。
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity - MoE 在大语言模型中应用的经典工作,系统化介绍了如何在 Transformer 中高效使用 Mixture of Experts 架构。
