SAM 2: Segment Anything in Images and Videos
一、论文基本信息
关键词:图像分割,视频分割,视频处理,可提示视觉分割(PVS)。
二、研究背景与问题定义
研究背景
现有图像分割模型的成功与局限性:“Segment Anything (SA)”模型(即 SAM),实现了“可提示的”(promptable)图像分割,即用户可以通过简单的提示(如点击、画框)就能快速分割出图像中的任何物体。这为图像分割提供了一个“基础模型”。然而,SAM 只能处理静态图片,无法直接应用于动态的视频数据。
视频数据在现实世界中的普遍性和重要性:现实世界中的视觉信息很大一部分以视频形式存在。在许多关键应用领域,如增强现实/虚拟现实 (AR/VR)、机器人技术、自动驾驶和视频编辑等,都需要对视频中的物体进行时空定位和分割,而不仅仅是图像级别的静态分割。
视频分割相比图像分割的额外挑战:
- 物体动态变化: 视频中的物体会发生运动、形变、遮挡、光照变化等,这使得在不同帧之间追踪和一致地分割同一物体变得非常困难。
- 视频质量问题: 视频可能因为相机抖动、模糊或低分辨率而质量较低,增加了分割难度。
- 效率要求: 视频包含大量帧,需要高效地处理,以实现实时或接近实时的分割。
现有视频分割模型和数据集的不足: 尽管已经存在一些视频分割模型和数据集,但它们在提供像 SAM 在图像领域那样“分割一切视频中物体”的通用能力方面仍有欠缺。现有数据集在规模、多样性和标注稠密性方面可能不足以训练出能处理任意视频分割任务的通用模型。
SAM 2 的目标是构建一个能够统一处理图像和视频分割的通用模型,并为此构建了史上最大的视频分割数据集。
问题定义
如何构建一个统一的视觉分割系统,能够以“可提示”(promptable)的方式,对图像和视频中的任意物体进行准确、高效的时空分割。
统一性 (Unified Model): 目标是开发一个模型,而不是两个独立的模型,能够同时处理图像分割(将图像视为单帧视频)和视频分割任务。意味着模型需要具备处理时间维度信息的能力。
可提示性 (Promptable): 沿袭了原始 SAM 的交互式分割范式。用户通过提供简单的提示(例如,在视频的任何一帧上点击点、画框或提供初始掩码)来指定感兴趣的物体。
任意物体分割 (Segment Anything): 模型应该能够识别并分割视频中出现的任何视觉实体,无论其类别、大小、形状或复杂程度如何。这要求模型具有强大的泛化能力。
时空分割 (Spatio-temporal Segmentation): 对于视频而言,问题不仅仅是分割单帧图片中的物体,更重要的是要追踪并分割该物体在整个时间维度上的运动和变化。意味着模型需要输出在视频所有相关帧中一致的、准确的“掩码序列”(masklet)。
Masklet (掩码序列) 指的是一个特定物体在视频中跨越多个帧的完整时空分割掩码序列。
对于一个单帧图像,我们谈论的是一个“分割掩码”(mask)。
对于一个视频中的一个物体,Masklet 就是这个物体从出现到消失,在每一帧中对应的所有分割掩码的集合,形成一个连贯的时空轨迹。准确性和效率: 最终的分割结果需要高精度,并且处理过程要足够高效,尤其是对于视频数据,要能实现实时或接近实时的处理能力。
三、核心方法 / 模型 / 系统设计
1. 任务定义:可提示视觉分割 (Promptable Visual Segmentation - PVS)
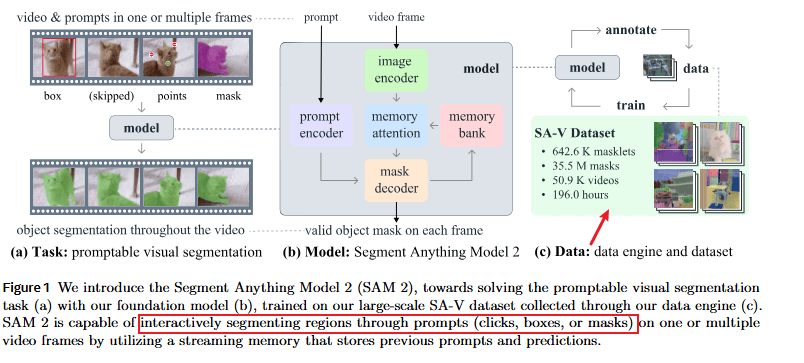
- 泛化图像分割到视频: PVS 任务将图像分割的概念扩展到视频领域。用户在视频的任意一帧提供提示(点、框或掩码),模型则预测该物体在整个视频中的时空掩码(即 Masklet)。
- 迭代式细化: 如果模型预测的 Masklet 不够准确,用户可以在后续帧中提供更多提示来迭代地细化它。
2. 模型架构:简单 Transformer 架构与流式记忆 (Streaming Memory)
SAM 2 的模型是基于一个简单、统一的 Transformer 架构,能够处理图像和视频数据。其关键特性是引入了“流式记忆”:
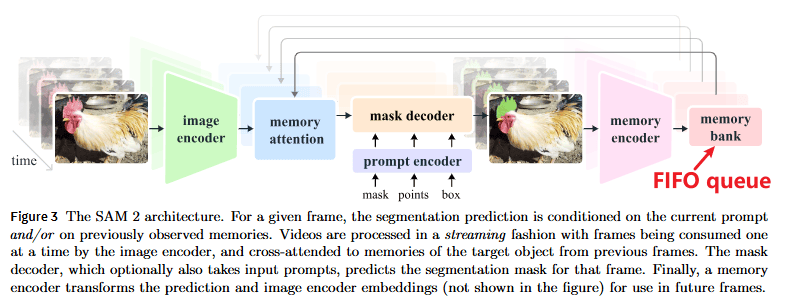
图像编码器 (Image Encoder): 类似于原始 SAM,用于提取输入图像或视频帧的视觉特征。论文中提到了使用 Hiera-B+ 和 Hiera-L 等编码器。
提示编码器 (Prompt Encoder): 用于编码用户提供的提示(点、框、掩码)。
轻量级掩码解码器 (Lightweight Mask Decoder): 接收图像特征、提示编码和记忆信息,然后预测输出掩码。
流式记忆模块 (Streaming Memory Module): 这是 SAM 2 区分于原始 SAM 的核心创新。
作用: 存储关于目标物体在之前帧中的信息和用户交互。
工作原理: 当模型处理视频帧时,它会利用这个记忆模块来“回忆”之前帧中目标对象的外观、位置和上下文信息。
记忆注意力 (Memory Attention): 模型通过一个记忆注意力机制来关注和整合来自记忆的上下文信息,从而帮助预测当前帧的分割掩码。
在 SAM 2 的
个 Transformer 块中,它们是串联工作的: - 先做自注意力: 模型先观察当前帧,弄清楚“这一帧里都有什么,边缘在哪里”。
- 再做交叉注意力: 模型拿着当前帧的特征,去翻看“记忆库”。它会比对:“这一帧里的这个形状,是不是就是前几帧用户点击过的那个杯子?”
- 循环往复: 每一层 Transformer 都在重复这个“看自己”和“看历史”的过程,最终精准地在当前帧勾勒出物体的 Mask。
统一性: 当处理图像时,记忆模块为空,模型行为与原始 SAM 类似。这使得模型能够无缝地在图像和视频任务之间切换。
实时视频处理: 这种流式架构允许模型逐帧处理视频,并通过记忆模块保持对目标的跟踪,从而实现实时或接近实时的视频分割。
3. 数据引擎:构建最大视频分割数据集 SA-V
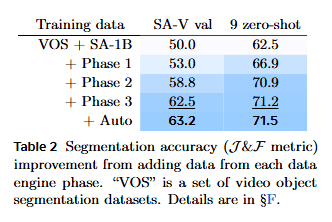
为了训练这个强大的通用模型,SAM 2 团队开发了一个“数据引擎”(data engine),用于迭代地改进模型和收集迄今为止最大的视频分割数据集 SA-V。数据引擎分为几个阶段:
- 人机协作 (Human-in-the-Loop): 模型预测初始分割,人类标注员根据预测结果进行修正。模型从这些修正中学习,然后生成更好的预测,形成一个正向循环。
- 多阶段标注协议:
- Phase 1 (SAM only): 初始阶段,标注员使用原始 SAM 进行逐帧手动高质量标注,耗时较长。
- Phase 2 (SAM + SAM 2 Mask): 引入早期 SAM 2 模型的预测作为辅助,标注员在此基础上进行修正,提高了效率。
- Phase 3 (SAM 2 in the loop): SAM 2 模型在循环中发挥更大作用,能够利用记忆生成 Masklet,标注员主要进行精修。效率进一步提升,同时保持高标注质量。
- 自动 Masklet 生成 (Auto Masklet Generation): 为了增加数据的多样性和覆盖范围,模型会自动生成大量 Masklet 候选,并经过验证(过滤)后添加到数据集中。这有助于识别模型失败案例,并将其反馈给标注员进行修正。
- 大规模数据: 最终,SA-V 数据集包含超过 50.9K 视频和 642.6K Masklets,显著大于现有视频对象分割 (VOS) 数据集。
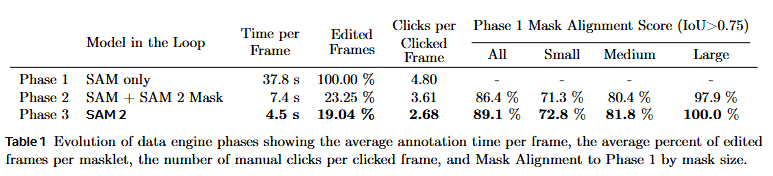
- **Phase 1 (SAM per frame)**:仅使用原始 SAM 进行逐帧标注。每帧耗时 37.8 秒,且 100% 的帧需人工编辑(平均 4.8 次点击),属于高成本的基准构建阶段。
- **Phase 2 (SAM + SAM 2 Mask)**:引入具备初步掩码传播能力的早期模型。每帧耗时降至 7.4 秒(提速约 5 倍),需编辑帧比例降至 **23.25%**,大幅减轻了空间标注压力。
- **Phase 3 (SAM 2 fully-featured)**:使用带记忆模块的完整模型。每帧仅需 4.5 秒(比阶段 1 快 8.4 倍),仅有 19.04% 的帧需少量点击修正(2.68 次),实现了极高的自动化程度。
- **质量验证 (Mask Alignment Score)**:该项指标旨在回答“速度变快后质量是否下降”。以 Phase 1 的纯人工标注为金标准(100%),计算后续阶段结果与 Phase 1 的重合度(IoU > 0.75 的比例)。结果显示:Phase 3 的整体对齐得分达到 **89.1%**,在大型物体(Large)上更达到了 **100%**。这证明了在效率提升 8 倍的同时,标注质量依然保持在极高水平。
4. 训练策略
- 多源数据混合训练: SAM 2 不仅在 SA-V 数据集上训练,还结合了现有的视频对象分割 (VOS) 数据集和原始 SAM 使用的 SA-1B 图像分割数据集,以及内部许可的视频数据。这种混合训练策略增强了模型的泛化能力。
- 迭代式数据改进: 随着数据引擎阶段的推进,模型会不断地在新增的、更优质、更稠密的标注数据上进行训练,从而持续提升性能。
在深度学习,特别是 Transformer 架构中,自注意力和交叉注意力是两类核心机制。它们的主要区别在于 Query (Q)、Key (K) 和 Value (V) 的来源。
1. 自注意力 (Self-Attention)
- 原理: Q、K、V 全部来自于同一个输入序列。它计算序列内部每个元素与其他所有元素之间的相关性。
- 优点:
- 捕捉内部结构: 能够学习同一帧或同一句子内部的全局依赖关系(例如,理解图片中物体的一部分与另一部分属于同一个整体)。
- 特征增强: 让每个位置的特征都融合了整张图的上下文,变得更加丰富。
- 缺点:
- 计算开销大: 复杂度是序列长度
的平方 ( )。在处理高分辨率图像时,计算量非常惊人。 - 缺乏外部引导: 它只在“看自己”,无法引入外部参考信息。
- 计算开销大: 复杂度是序列长度
- 使用场景:
- 特征提取阶段: 在 SAM 2 中,当前帧进入模型后先做自注意力,目的是为了理解当前帧的视觉结构。
- 语义理解: NLP 中理解句子内部的语法关系。
2. 交叉注意力 (Cross-Attention)
- 原理: Q 来自当前输入(例如当前帧),而 K 和 V 来自另一个外部来源(例如记忆库中的历史帧)。
- 优点:
- 信息对齐与匹配: 能够非常有效地在一个序列中查找另一个序列的相关信息。它是“跨域”交流的桥梁。
- 聚焦能力: 让当前帧能够根据历史信息(提示、旧掩码)精准地定位目标物体。
- 缺点:
- 依赖外部质量: 如果 K 和 V(记忆库)的信息是错误的或模糊的,交叉注意力的效果会大打折扣。
- 异步开销: 需要维护和处理额外的记忆数据,增加了系统设计的复杂度。
- 使用场景:
- 跨时空匹配: SAM 2 的核心场景。 用当前帧作为 Q,去记忆库(K、V)里搜寻:“我要找的那个物体在这一帧的哪里?”
- 多模态融合: 比如根据文字提示(Q)去图像(K、V)中寻找对应的物体。
总结对比
| 特性 | 自注意力 (Self-Attention) | 交叉注意力 (Cross-Attention) |
|---|---|---|
| Q, K, V 来源 | 全部来自同一来源 | Q 来自当前,K/V 来自外部 |
| 核心目的 | 建模内部关系,增强自身特征 | 寻找相关性,引入外部上下文 |
| 打个比方 | 独自思考,把知识点串联起来 | 查字典,把问题和答案对应起来 |
| SAM 2 作用 | 理解当前帧的画面布局 | 跨帧追踪,把物体“粘”在目标上 |
通过这种组合,SAM 2 既保持了对当前图像细节的敏感度(自注意力),又具备了跨越时间的稳定追踪能力(交叉注意力)。
四、实验
数据集对比
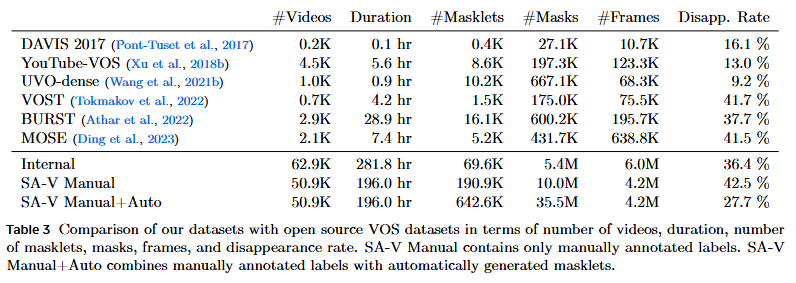
zero-shot(零样本实验)
稠密标注(dense annotation):在一个图片或视频帧中,对几乎所有感兴趣的物体都进行了细致、全面的标注。
SAM2的目标是分割一切,是图像分割的通用模型,物体数量多,覆盖范围广,细节精度高,层级信息丰富
评价指标:
- J&F(越高越好):
Jaccard 相似度 (J):也被称为 IoU (Intersection over Union),它计算的是预测分割区域和真实分割区域的交集与并集的比值。它的值介于 0 到 1 之间,值越高表示预测结果与真实结果的重叠度越高,也就是分割得越准确。
F-measure (F):是准确率 (Precision) 和召回率 (Recall) 的调和平均值。它综合考虑了模型的查准率和查全率,能够更全面地评估分割结果的质量。F-measure 的值也介于 0 到 1 之间,值越高表示模型的分割效果越好。(区分准确率和召回率的方法,准确率(Precision) 的分母是 所有被模型预测为阳性 的。它问的是:在我“声称”的所有阳性中,有多少是“准确”的?
召回率(Recall) 的分母是 所有实际为阳性 的。它问的是:在所有“真实存在”的阳性中,模型“回忆”起了多少?,即准预测召实际)
SAM 2 的实验部分非常详尽,旨在证明其作为视频分割“基础模型”的通用能力。实验主要分为三个核心领域:可提示视频分割(PVS)、传统视频对象分割(VOS)以及静态图像分割。
1. Baseline(基准模型)
由于 SAM 2 是首个真正意义上“分割一切”的视频基础模型,为了公平对比,作者构建了两个极强的组合式 Baseline,代表了当时的 SOTA(最先进)水平:
- **SAM + XMem++**:将原始 SAM 的图像分割能力与 XMem++(一种强力的长视频对象分割模型)结合。
- SAM + Cutie:将 SAM 与 Cutie(目前顶级的视频对象分割模型,擅长处理复杂的物体交互)结合。
- 对比方式:在交互式任务中,先用 SAM 生成第一帧的掩码,然后用 XMem++ 或 Cutie 进行跨帧追踪;如果后续帧需要修正,再次调用 SAM。
2. 实验领域与结果
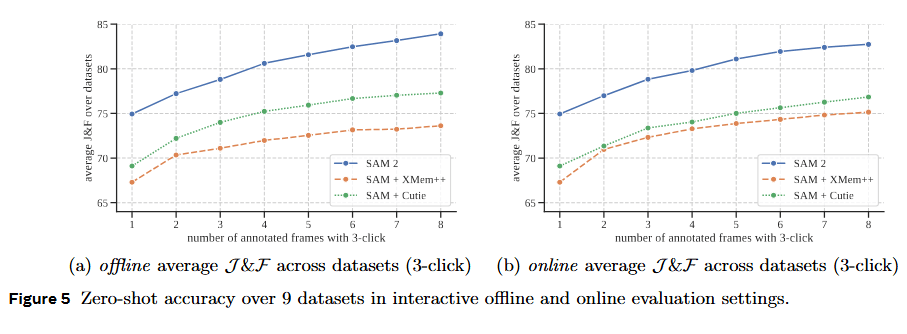
A. 可提示视频分割 (PVS) —— 交互式评估
这是最贴近用户实际体验的设置。模型在处理视频时,允许在任意帧进行多次点击(3-click)修正。
- 实验设置:分为 Offline(离线) 和 Online(在线) 两种模式。离线模式允许模型反复查看全视频来寻找错误最大的帧进行修正;在线模式模拟人类一次性看完整段视频。
- 结果:SAM 2 在所有 9 个零样本(zero-shot)数据集上均显著优于“SAM + XMem++”和“SAM + Cutie”,SAM 2 达到同等精度所需的交互次数比 Baseline 少 3 倍以上。。
B. 半监督视频对象分割 (VOS) —— 传统任务
这是视频分割的经典榜单,只给定第一帧的 Ground-truth 掩码,要求模型追踪全视频。
- 对比对象:STCN, SwinB-DeAOT, XMem, Cutie 等。
- 结果:在多个主流数据集(MOSE, DAVIS 2017, YouTube-VOS)上,SAM 2 全面超越了之前的 SOTA 模型。
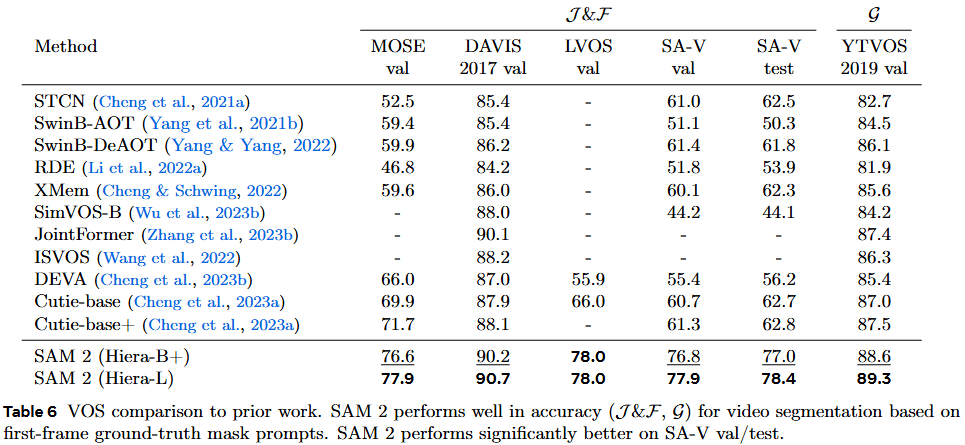
- SA-V Benchmark:在作者自己提出的更具挑战性的 SA-V 测试集上,SAM 2 的优势更加巨大(比最强 Baseline Cutie 高出约 15 个点),证明了传统模型在处理“非显著物体”和“复杂遮挡”时的乏力。
C. 静态图像分割
为了证明它是“统一模型”,作者在图像分割上也进行了测试。
- 对比对象:原始 SAM。
- 结果:
- 精度更高:在 23 个数据集上,1-click mIoU 超过了 SAM。
- 速度更快:得益于更高效的 Hiera 图像编码器,SAM 2 的推理速度比 SAM 快 6 倍。

3. 消融实验 (Ablation Studies)
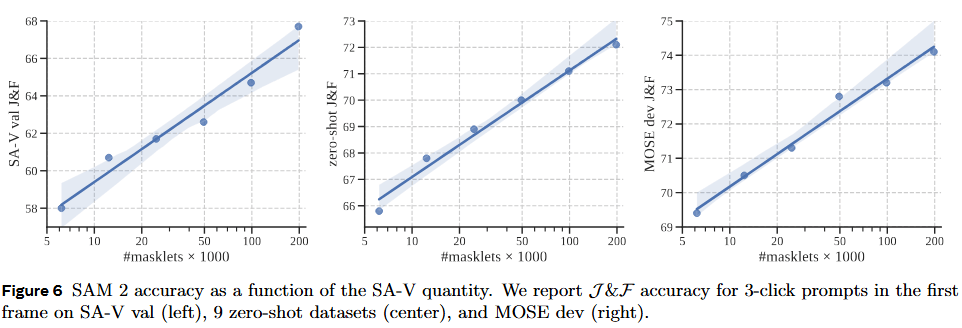
- **数据量 (Figure 6)**:随着 SA-V 数据集规模的扩大,模型性能呈现清晰的“幂律”增长,且目前尚未看到饱和迹象,说明更多数据依然能让模型变强。
- **记忆模块 (Table 11)**:
- Object Pointers(对象指针)的作用巨大:加入后在长视频数据集(LVOSv2)上提升显著,证明轻量级的语义向量对解决“消失后再出现”问题至关重要。
- 对比 GRU:发现简单的 Transformer 结构比复杂的循环神经单元(GRU)效果更好且更简洁。

五、创新点、贡献与改进空间
1. 核心创新点 (Key Innovations)
- 统一的流式架构 (Unified Streaming Architecture):
打破了“图像分割模型 + 视频跟踪器”的传统组合模式。SAM 2 采用单体 Transformer 架构,通过记忆注意力机制 (Memory Attention) 实时融合过去的信息,实现了图像和视频在算法底层的完全统一。 - 流式记忆机制 (Streaming Memory Mechanism):
引入了由个最近帧、** 个提示帧以及轻量级对象指针 (Object Pointers)** 组成的先进先出队列记忆库。这种设计允许模型在处理长视频时,既能保留初始定义的“锚点”,又能适应物体当前的外观变化,并有效处理物体消失后重现的情况。 - 多掩码预测与歧义处理:
针对视频中的空间和时间歧义(例如点击一个零件是想分割零件还是整体),模型会在每一帧预测多个掩码,并选择 IoU 评分最高的进行传播,同时允许后续提示实时修正歧义。
2. 主要贡献 (Main Contributions)
- 提出新任务 (PVS):
定义了可提示视觉分割 (Promptable Visual Segmentation) 任务,将交互式分割从静态图像领域推向了动态视频领域,支持在视频任意时间点进行多轮交互修正。 - 最大数据集 (SA-V):
发布了包含 50.9K 视频和 642.6K 掩码序列 (Masklets) 的数据集。其规模比现有同类数据集大一个数量级,且包含了大量具有挑战性的遮挡、复杂运动和非显著物体。 - 高效的数据引擎 (Data Engine):
展示了一套高效的人机协作标注系统。通过模型迭代辅助,将标注效率提升了 8.4 倍,证明了“模型引导标注 -> 数据强化模型”这种闭环路径在视频领域的巨大成功。 - 卓越的性能与速度:
在 17 个视频数据集的零样本测试中全面超越 SOTA。同时,其推理速度支持实时处理(B+ 版本达 44 FPS),且在图像分割上比原始 SAM 快 6 倍。
3. 改进空间与局限性 (Future Work & Limitations)
- 跨视频目标关联 (Inter-video Association):
目前的 SAM 2 擅长在单个视频内追踪物体。但在处理多个相关视频(如不同角度拍摄同一物体)时,如何实现跨视频的对象一致性仍有待研究。 - 极其细长物体的丢失:
在处理非常细长的目标或极其剧烈的视角变换时,模型有时会丢失目标。 - 多目标交互时的混淆:
在多个极其相似的物体频繁交叉、遮挡(如一群穿同样衣服的球员)时,记忆模块可能会出现身份分配错误。 - 计算资源需求:
虽然模型支持实时推理,但在进行超长视频的复杂交互标注时,对显存的占用和对算力的需求对于普通移动设备或低端 GPU 仍是挑战。 - 幻觉与伪影:
在极低分辨率或极强模糊的视频中,模型有时会生成不符合物理常识的掩码边缘(幻觉)。
六、我的思考
- 实时性(44 FPS)是建立在 A100 这种高端显卡上的,边缘端的落地仍有挑战,要同时维护高分辨率的自注意力和庞大的记忆库,功耗和内存带宽可能是瓶颈,可以尝试边缘端实时视频分割的模型。
- 有时,提出一个新任务比提出一个新模型更有价值
- 模型复杂的话,可以采用”自顶向下”的写法,将Model单独列成一个大标题,各个模块用二级标题表示
- 大型通用基座模型的消融实验基本上都是放在附录的,通过对数据量进行幂律分布分析,说明是数据量的作用还是真的模型起作用
- 如果一张图左边很密,右边一定要有留白或者对应的文字说明。
- 图注(Caption)有时要足够长,确保读者不看正文也能通过看图和读图注看懂大致意思。
七、其他
可跟进的文献
@misc{carionThu Nov 20 2025 18:59:56 GMT+0000 (Coordinated Universal Time)samsegmentanything,
title={SAM 3: Segment Anything with Concepts},
author={Nicolas Carion and Laura Gustafson and Yuan-Ting Hu and Shoubhik Debnath and Ronghang Hu and Didac Suris and Chaitanya Ryali and Kalyan Vasudev Alwala and Haitham Khedr and Andrew Huang and Jie Lei and Tengyu Ma and Baishan Guo and Arpit Kalla and Markus Marks and Joseph Greer and Meng Wang and Peize Sun and Roman Rädle and Triantafyllos Afouras and Effrosyni Mavroudi and Katherine Xu and Tsung-Han Wu and Yu Zhou and Liliane Momeni and Rishi Hazra and Shuangrui Ding and Sagar Vaze and Francois Porcher and Feng Li and Siyuan Li and Aishwarya Kamath and Ho Kei Cheng and Piotr Dollár and Nikhila Ravi and Kate Saenko and Pengchuan Zhang and Christoph Feichtenhofer},
year={Thu Nov 20 2025 18:59:56 GMT+0000 (Coordinated Universal Time)},
eprint={2511.16719},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2511.16719},
}